【小技巧】SEO搜索引擎优化
工作中运营上遇到了技术问题,有关SEO的东西还挺多的,整理记录一下,以Google搜索引擎为例
网站所有权验证
首先要让搜索引擎先验证我们对网站的所有权,Google搜索引擎提交的入口为:Google Search Console
验证你对该网站的所有权有多种方式,我这里使用的是Hexo->butterfly主题中提供的”Google Analytics”验证方式
在_config.butterfly.yml中可以找到_config.butterfly.yml中 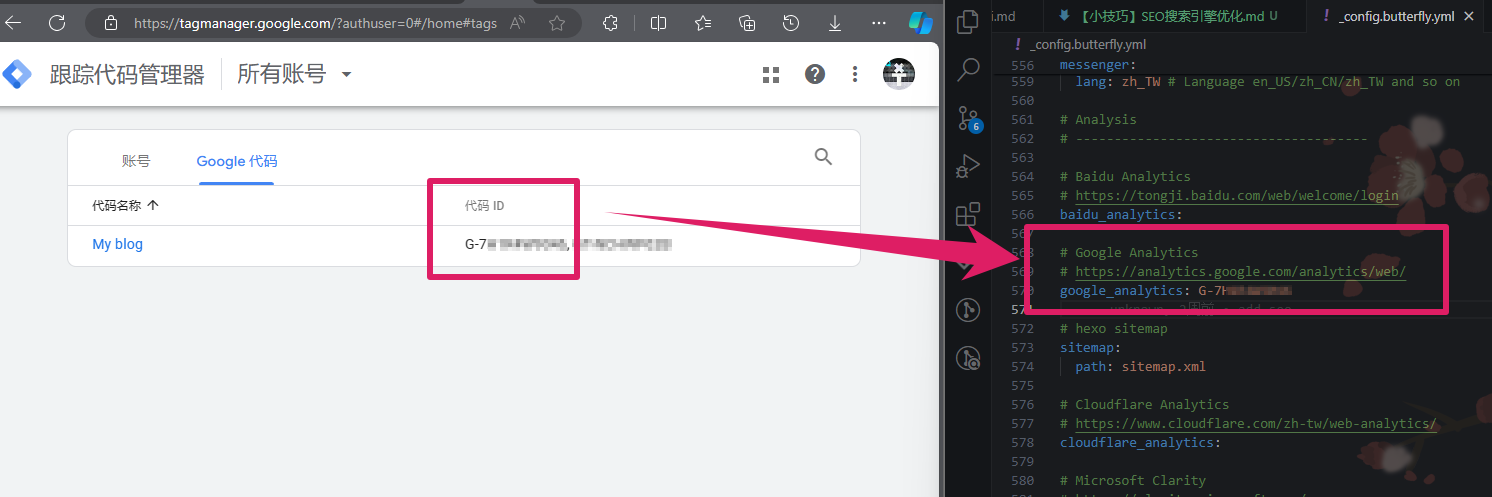
添加后部署一下,在Google Search Console或Google Analytics中刷新一下,就能看到验证成功了
SEO优化记录
搜索结果显示
简单说就是截图的这玩意儿
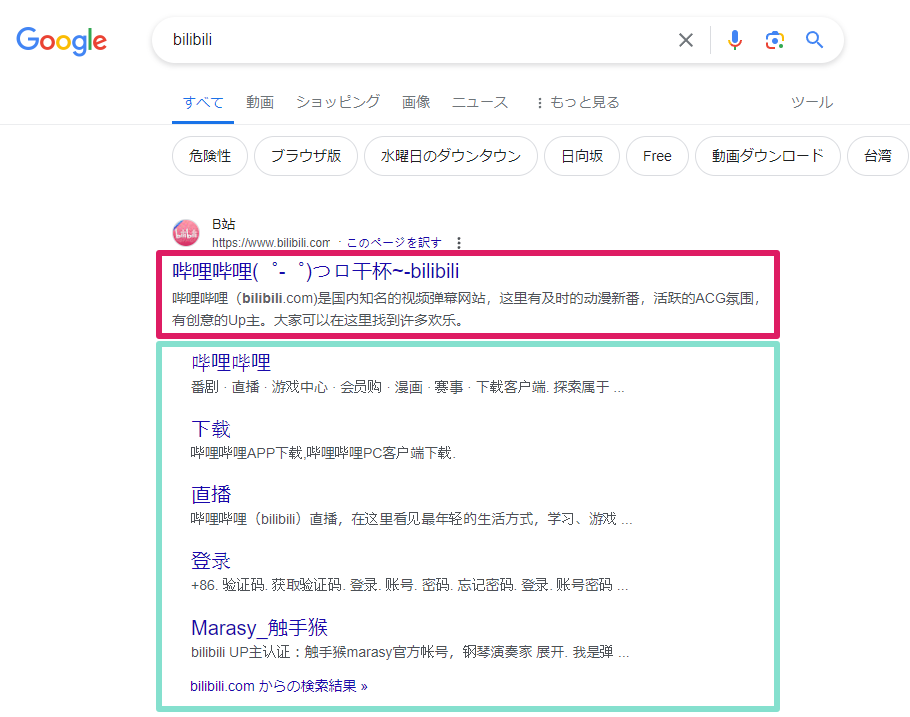
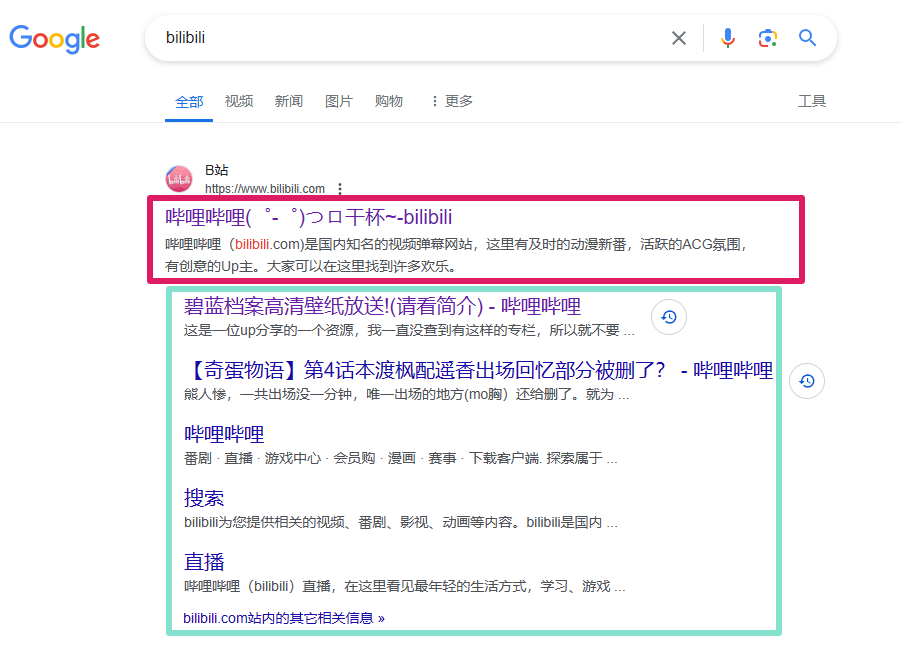
标题及摘要
图中 红框 标注的部分
这个其实是index.html文件中的<title>标签和<meta name="description">标签内容,改掉即可
但是,工作上要求支持
-zh-CN或-ja
站内链接
图中 绿框 标注的部分
它的实现原理是,诸如谷歌一类的搜索引擎,有一个爬虫程序,会定期爬取你的网站,然后根据爬取到的内容,生成一个索引并展现在搜索结果中。
因此,只要在新增 routes时
否则,可能需要单独添加 sitemap.xml文件
站点地图
以Hexo为例,添加站点地图
点击查看内容
生成sitemap文件
- 安装相关插件
1
npm install hexo-generator-sitemap --save - 修改配置
修改站点主题配置文件 _config.butterfly.yml, 添加如下两段配置1
2
3# hexo sitemap
sitemap:
path: sitemap.xml
- 安装相关插件
重新编译博客:
hexo g
看看在public文件夹里面是不是出现了sitemap.xml文件,你还可以本地访问http://localhost:4000/sitemap.xml 查看效果,说明配置成功搜索引擎收录
谷歌操作比较简单,就是向Google Search Console提交sitemap:
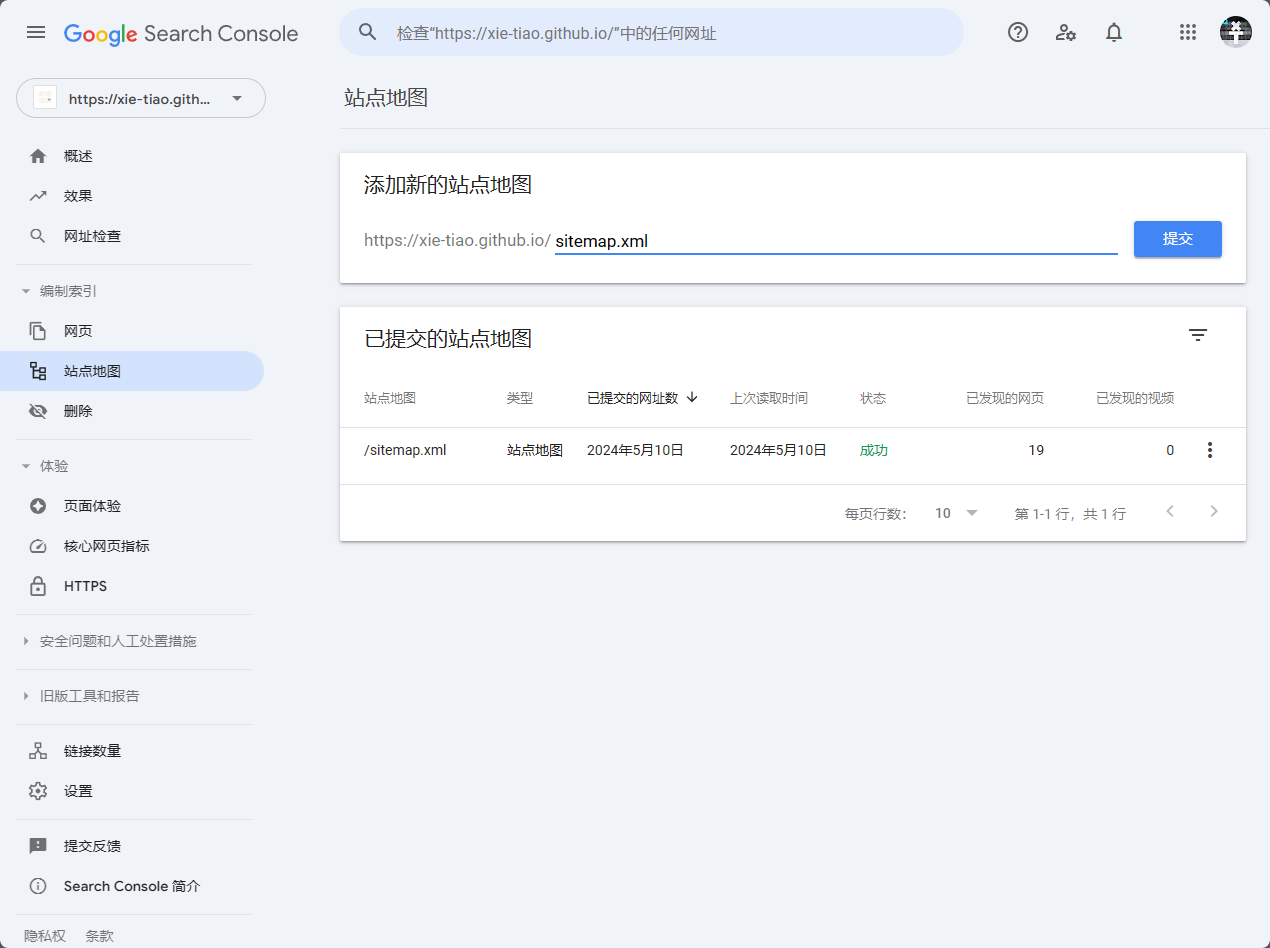
值得注意的一点是,尽量不要在站点 URL(Universal Resource Locator,统一资源定位符) 上加
#,井号:表示网页中的一个位置,被称之为锚点,常用于
简单的说就是在一个网页中,URL不变的情况下,通过添加“#buy”的字符在URL最后可以跳转到当前网页中已经定义好的锚点(id=“buy”)位置
比如我们写Hexo博客就可以利用这个跳转不同标题H1H2H3:
搜索引擎的爬虫程序会默认#之后的url为锚点,这样在生成站内链接时也会产生影响
因此,在新增routes时最好使用History模式,而非Hash模式:
以vue为例:
点击查看内容
1 | |
其他优化
文章链接优化
添加蜘蛛协议robots.txt
点击查看内容
robots.txt(统一小写)是一种存放于网站根目录下的 ASCII 编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
在根目录 source 文件下新建 robots.txt 文件,添加以下文件内容(将 Sitemap 中的域名切换成自己网站域名)
1 | |
参数说明: User-agent: * 允许所有 robot 访问,Allow 允许访问 X 目录,Disallow 禁止访问 X 目录
数据结构化标记
Google搜索支持的结构化数据标记
这个功能需要根据结构化语法自己写,示例谷歌官方已给出,不再赘述
其他抓取优化
link标签
相似的域名可能会让爬虫程序混乱,比如
baidu.com与www.baidu.com,这种情况下最好单独指定网址
可通过在每个非规范版本的 HTML 网页的<head>部分中,添加一个rel="canonical"链接来进行指定规范网址。
1 | |
语义化标签
<h1><h2><p>之类的就不用说了,这里主要强调<img>
添加<img>最好把alt属性也加上,
参考文献
- 微信
- 支付宝

